Visualize model in keras (ubuntu)
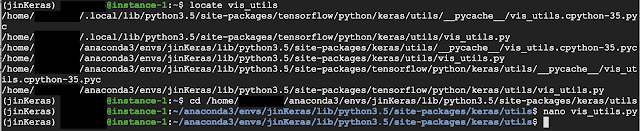
Step1. 安裝相關套件 #安裝相關套件 sudo apt-get install graphviz conda install graphviz conda install pydotplus pip install pydot Step2. 修改vis_utils.py檔 利用指令locate找到vis_utils.py檔 sudo updatedb locate vis_utils (此時找到的路徑可能不只一個)選擇路徑(site-packages/keras/utils)中的vis_utils檔,並修改檔內的函式model_to_dot() cd /home/yourID/anaconda3/envs/jinKeras/lib/python3.5/site-packages/keras/utils nano vis_utils.py 將其中的layers = model.layers改為layers = model._layers: Step3. 於程式碼中繪出model #import from keras.utils.vis_utils import model_to_dot # build/load model here #write out model figure in png if_show_shapes=True if_show_layer_names=True plot_model(model,show_shapes =if_show_shapes, show_layer_names =if_show_layer_names , to_file='modelFigure.png') Note. 若無修改vis_utils的步驟則輸出的模型圖在input layer的地方將會有亂碼產生



